
Rally Lookback API User Manual
OPEN PREVIEW DOCUMENTATION
Note: The Lookback API is only available in the Production SAAS environment.
It is not available in Sandbox, Demo, or OnPremises instances.
Overview
The Rally Lookback API provides access to the revision history of your data stored in the Rally Platform. It allows you to execute queries against the history of User Stories, Defects, Tasks, and other work items using a MongoDB-like query syntax.
Release status
The Rally Lookback API is currently in Open Preview. Changes made within Rally usually appear in the Rally Lookback API within 15-60 seconds.
Data Model
The Rally Lookback API stores the history of work items from Rally in a format suitable for a broad range of queries.
Each work item has one or more snapshots that represent the state of the item at different periods in the past. Each snapshot is made up of:
_idthat uniquely identifies the snapshotObjectIDequal to the item's ObjectID in Rally_ObjectUUIDequal to the item's_refObjectUUIDin the Rally Web Service API_ValidFromand_ValidTodates that indicate the time period which the snapshot represents- the state of the item including the values of all its fields
_PreviousValuesof fields that were changed_SnapshotNumbera sequentially increasing number snapshot number for each work item
Example
URI: https://rally1.rallydev.com/analytics/v2.0/service/rally/workspace/1234/artifact/snapshot/query.js
POST data:
{
"find": {
"ObjectID": 10448843790
},
"fields": ["State", "_ValidFrom", "_ValidTo", "ObjectID", "FormattedID"],
"hydrate": ["State"],
"compress": true
}The example above:
- Searches for all snapshots for
ObjectID10448843790 - Includes the
State,_ValidFrom,_ValidTo,ObjectID,FormattedIDfields in the results - Hydrates the
Statefield with a text value instead of its default of an integer foreign key - Combines snapshots where the changes were to fields we did not request.
The above query generates the response:
... // response metadata omitted
"Results": [
{
"_ValidFrom": "2013-02-07T02:15:58.719Z",
"_ValidTo": "2013-02-07T03:17:59.444Z",
"ObjectID": 10448843790,
"State": "Submitted",
"FormattedID": "DE16129"
},
{
"_ValidFrom": "2013-02-07T03:17:59.444Z",
"_ValidTo": "9999-01-01T00:00:00.000Z",
"ObjectID": 10448843790,
"State": "Open",
"FormattedID": "DE16129"
}
]ObjectID: 10448843790 in both records indicates both snapshots are for the same work item- The difference between the two snapshots is that the
Statefield was changed from "Submitted" to "Open" - The
_ValidTo: "2013-02-07T03:17:59.444Z" on the first snapshot matches the_ValidFromdate on the second snapshot, indicating the time at which the change was made. The time stamps are in GMT. _ValidTo: on the second snapshot has the far-future date: "9999-01-01T00:00:00Z", indicating it is the current state of the item. If another change were made toObjectID: 10448843790, the_ValidTodate of this snapshot would be updated to reflect when the change was made.
Deleted or Recycled Work Items
When a work item is deleted from Rally, the _ValidTo date on its current
snapshot is updated to reflect the time of deletion. If the work item is later
restored from recycling bin, a new snapshot is created with _ValidFrom date containing the time
at which the item was restored. This will create a gap in the timeline of
snapshots. The previous snapshot's _ValidTo will not equal the current
snapshot's _ValidFrom as would normally occur
when an item is updated.
Field Names
Fields that start with an underscore ("_") are fields that do not exist in Rally's
Web Services API and are provided for the convenience of analytics queries.
e.g. _SnapshotNumber, _id, _ValidFrom, _ValidTo, _PreviousValues
Custom fields are prefixed with "c_". e.g. c_KanbanState
Other fields match the field names in Rally's Web Services API.
Using the Rally Lookback API
API Endpoint
The base URL for Rally Lookback API query is:
https://rally1.rallydev.com/analytics/v2.0/service/rally/workspace/1234/- <workspaceOID> is your workspace Object ID. Your workspace Object ID can be retrieved from Rally's Web Services API.
Queries can be executed via POST or GET to the query endpoint:
POST:
URI: https://rally1.rallydev.com/analytics/v2.0/service/rally/workspace/1234/artifact/snapshot/query.js
POST data:
{
"find": { "ObjectID": 10448843790 },
"fields": ["_ValidFrom", "_ValidTo", "ObjectID", "State"],
"start": 0,
"pagesize": 1
}GET:
https://rally1.rallydev.com/analytics/v2.0/service/rally/workspace/1234/artifact/snapshot/query.js?find={"ObjectID":10448843790}&fields=["_ValidFrom","_ValidTo","ObjectID","State"]&start=0&pagesize=1Note:
- Endpoints also support the .json extension.
Authentication
The preferred method of authentication is a valid ZSESSIONID header or API Key in the HTTP request. A ZSESSIONID header is returned by Rally upon successful login.
Note: Browsers will prompt for basic authentication if a valid ZSESSION header is not provided. Basic authentication is supported unless SSO is enabled for your subscription.
Querying
A Query to the Rally Lookback API is made up of a required find parameter and zero or more options.
Example Query
URI: https://rally1.rallydev.com/analytics/v2.0/service/rally/workspace/1234/artifact/snapshot/query.js
POST data:
{
"find": {
"_ProjectHierarchy": 279050021,
"_TypeHierarchy": "Defect",
"State": { "$lt": "Closed" },
"__At": "current"
},
"fields": ["Name", "State", "FormattedID"],
"hydrate": ["State"],
"start": 10,
"pagesize": 10
}The above example:
- Submits a query to version 2.0 of the Rally Lookback API.
- Searches for all defects that are not currently closed under item 279050021 in the project hierarchy.
The response will consist of:
- The current snapshot for any matching defect.
- Include the fields:
Name,State, andFormattedID. - The
Statefield will be hydrated with its text value instead of its object id. See Hydration for more information. - Skips the first 10 snapshots and returns the next 10.
Search Criteria
The find parameter contains the search
criteria for the query. The query syntax used by the Rally Lookback
API is based on the syntax used by MongoDB with some modifications.
Supported Operators
The following operators are supported by the find parameter:
{a: 10}- docs where a is 10 or an array containing the value 10{a: 10, b: "hello"}- docs where a is 10 and b is "hello"{a: {$gt: 10}}- docs where a > 10, also $lt, $gte, and $lte{a: {$ne: 10}}- docs where a != 10{a: {$in: [10, "hello"]}}- docs where a is either 10 or "hello"{a: {$exists: true}}- docs containing an "a" field{a: {$exists: false}}- docs not containing an "a" field{a: {$regex: "^foo.*bar"}}- docs where a matches the regular expression /^foo.*bar/. Note, regex literal form (/.../) is not supported. Also, we recommend that you start regex searches with a "^" (indicating the start of the string) wherever possible because that may enable the use of an index.{"a.b": 10}- docs where a is an embedded document where b is 10{$or: [{a: 1}, {b: 2}]}- docs where a is 1 or b is 2{$and: [{a: 1}, {b: 2}]}- docs where a is 1 and b is 2
The following operators are not supported:
{a: {$nin: [10, "hello"]}}
Querying by Date
Every snapshot contains a _ValidFrom and _ValidTo field which together
indicate the time period for which the snapshot is valid. When querying by date,
the special field __At is available as a short-hand
for "valid at a specified time". __At can only be used with the
equality operator.
Examples:
The current snapshot for object 777.
{
"find": {
"ObjectID": 777,
"__At": "current"
}
}The current snapshot for object 777 (functionally identical to previous example).
{
"find": {
"ObjectID": 777,
"_ValidTo": { "$gt": "current" },
"_ValidFrom": { "$lte": "current" }
}
}All snapshots for object 777 that were created during 2013.
{
"find": {
"ObjectID": 777,
"_ValidFrom": {
"$gte": "2013",
"$lt": "2014"
}
}
}The snapshot identified by the given UUID
{
"find": {
"_ObjectUUID": "cb2cf39d-74f3-4b22-bee5-d2dea4a4bc10",
"__At": "current"
}
}_ValidFrom and _ValidTo support the following
operators:
- equals (for example
{"_ValidFrom": "2011-01-01TZ"}) $gt$gte$lt$lte$ne
__At only works with the equality
operator.
Date Formats
All Dates and times in the snapshot schema are GMT and represented as ISO-8601 date strings.
Queries against the fields _ValidFrom, _ValidTo and __At have full support for ISO-8601 date
string formats including week numbers, day of the year, ordinal dates,
etc.
Queries against other date fields only support the canonical forms of ISO-8601 (yyyy-mm-ddTZ, yyyy-mm-ddThh:mm:ssZ, and yyyy-mm-ddThh:mm:ss.lllZ as well as forms with trailing time shifts like -05:00). The regex used is:
/\d{4}-\d\d-\d\dT?(\d\d(:\d\d)?(:\d\d)?(\.\d{1,3})?)?((Z|((\+|-)?\d\d(:?\d\d)?)))?/Special Case: FormattedID
FormattedID is the ID that is
normally displayed within Rally for defects, stories, etc (e.g.
DE7654, S1234). Due to some internal implementation details, the FormattedID field only supports a
subset of the available operators:
- Supported:
$and,$or,$ne,$in, and$exists, including all recursive combinations of$andand$or. - Not Supported:
$lt,$lte,$gt,$gte,$all,$nin,$nor
FormattedID is a generated field
created by combining _UnformattedID and _TypeHierarchy. It does not exist
in the internal snapshot schema. The search criteria { FormattedID: "DE1234" } is
transparently translated into:
{ "_UnformattedID": 1234, "_TypeHierarchy": "Defect" }If you are having trouble developing complicated queries using FormattedID or need to use
operators not supported by FormattedID, try recomposing the
query using _UnformattedID or ObjectID.
Special Case: Drop-Down Fields
While they may look like simple string fields, the values for drop-down fields in
Rally are actually foreign keys specified with integer ObjectIDs. However, it is possible
to query drop-down fields using the string value. The API will silently convert
the specified string to the correct ObjectID.
{ "State": "Open" }is converted to..
{ "State": 41529051 }The allowed values for drop-down fields are specific to the Rally work item type. So the allowed values for the State field for Tasks are different than the State field for Defects. When you submit a query against a drop-down field, it will try to match the provided drop-down value(s) against any type that might have that value. In most cases, this is what you want. So:
{ "Priority": "High" }However, if you want to restrict your query to a particular work item type, you can do so by including an _TypeHierarchy clause in your query:
{ "_TypeHierarchy": "Defect", "Priority": "High" }Since drop-down fields have an ordered list of possible values, inequality comparisons can be done against drop-down fields:
{ "c_KanbanState": { "$lt": "In Progress" }}In the above example, the Rally Lookback API will first find all types
that have a KanbanState field and find the
ordered list of values for that type. Let's say you have following possible
values for KanbanState:
HierarchicalRequirement.KanbanState ∈ ['Ready', 'In Progress', 'Done']
Defect.KanbanState ∈ ['Triage', 'Ready', 'In Progress', 'Done']The Rally Lookback API will expand the above query into the following:
{"c_KanbanState": { "$in": [null, "Triage", "Ready"]}Notice how "null" is an automatically-added lowest order value. This means that
any work item where the KanbanState field is "<No
Entry>" will match the above clause.
Indices
When designing queries, it is important to be aware of the available indices. Queries that utilize indices will respond much faster and place less load on the system.
The Rally Lookback API has indicies on the following fields:
_idObjectID_ItemHierarchy_ProjectHierarchy_TypeHierarchy_UnformattedID_ValidFrom- When querying by
_ValidFrom, an index is also available on_ValidTo
- When querying by
IterationPortfolioItemProjectReleaseScheduleStateStateTags
Note:
- When using a Regex operator, starting the regex with a
^character will allow it to use an index if available. - All compound indices are defined in ascending order.
Search Options
Included Fields
Fields that are included in the results can be specified using the fields parameter. The default value
for fields is "false". When fields is false, then only the
minimum fields for each snapshot are returned in the response (see the Response
section below for the list of minimum fields).
**Note: this behavior is the opposite of MongoDB which will return the full documents by default. **
Most commonly, you will provide a list of fields you want included in the response:
{
"find": { ... },
"fields": [ "Name", "PlanEstimate" ]
}MongoDB's Object format for field specifications is also supported:
{
"find": { ... },
"fields": { "Name": 1, "PlanEstimate": 1 }
}The Object format allows for the use of the slice operator to return a particular element in an array value.
"fields": { "_TypeHierarchy": { "$slice": -1 }} - last value
"fields": { "_TypeHierarchy": { "$slice": [0,2] }} - first 2 values
"fields": { "_TypeHierarchy": { "$slice": [-1,2] }} - last 2 valuesThe following are some other examples and the expected behavior:
"fields": false - default fields
"fields": [] - error
"fields": {} - errorDuring development, it is possible to return almost all fields by setting fields to "true". Doing so will
reduce the maximum allowed records per query. We strongly encourage you specify
a list of fields in your production application.
"fields": trueSetting fields to "true" will not return
the FormattedID. To populate the FormattedID in the results, it must
be specified using the list or object formats.
"fields": { "FormattedID": 1 }
"fields": [ "FormattedID" ]For an explanation why we didn't use "fetch" like Rally's Web Services API, see the FAQ.
Hydrating Drop-Down Fields
By default, during the response, the Rally Lookback API does not
attempt to convert (hydrate) drop-down field values from their native ObjectID integer form into strings.
So a query like this:
{
"find": { "_TypeHierarchy": "Defect" },
"fields": [ "ScheduleState", "State" ]
}would return results like this:
"Results": [
{
"ScheduleState": 41529075
"State": 41529053
},
{
"ScheduleState": 41529075
"State": 41529053
},
...
]However, you can specify fields to be hydrated using this syntax:
"find": { "_Type": "Defect" },
"fields": [ "ScheduleState", "State" ],
"hydrate": [ "ScheduleState", "State" ]This will hydrate the ScheduleState and State fields back
into strings, like this:
"Results": [
{
"ScheduleState": "Defined"
"State": "Closed"
},
{
"ScheduleState": "Defined"
"State": "Closed"
},
...
]The following fields are hydrated by default if they are included in the requested fields:
- Package
- TaskStatus, DefectStatus, TestCaseStatus
- Type on Test Case items
- State on Task items
Note:
- The Rally Lookback API will use the current allowed values to do this hydration. It is possible that there are older values referenced in the snapshots. Those OIDs will not be hydrated and a warning will be returned.
- Changes or additions to the allowed values list in Rally may take a full day before they are reflected in the Rally Lookback API.
- It is not possible to hydrate some field types (e.g. User). Trying to hydrate a field that is not hydrate-able will produce a warning.
Hydrating Previous Values
You also may hydrate the values that are returned in the _PreviousValues array. The syntax
for hydration of _PreviousValues is similar to the
general hydration syntax. For example, if you wanted to hydrate the previous
ScheduleState value, you would
specify it with this syntax:
{
"find": {
"_TypeHierarchy": { "$in" : [ "HierarchicalRequirement", "Defect" ] },
"ScheduleState": { "$gte": "Accepted" },
"_PreviousValues.ScheduleState": { "$lt": "Accepted" },
"AcceptedDate": { "$gte": "2014-02-01TZ" }
},
"fields": ["ScheduleState", "Name", "_PreviousValues.ScheduleState"],
"hydrate": ["ScheduleState", "_PreviousValues.ScheduleState"]
}This will result in:
"Results": [
{
"ScheduleState": "Accepted",
"Name": "Some story name",
"_PreviousValues": {
"ScheduleState": "Completed"
}
},
{ ... }
]Note:
- Attempting to hydrate all
_PreviousValueswith"hydrate": ["_PreviousValues"]is not supported. Each member of_PreviousValuesmust be specified individually. - Quotes are required around
_PreviousValuesfield names:"hydrate": [ "_PreviousValues.ScheduleState" ]
Hydrating Iteration and Release
The attributes of Iteration and Release are available through hydration. When specifying "hydrate": ["Iteration"], the snapshot will contain the following attributes:
"Iteration": {
"ObjectID": 12345,
"Name": "Iteration 3",
"StartDate": "2014-07-01 17:00:00.0",
"EndDate": "2014-07-14 16:59:59.0"
}When specifying "hydrate": ["Release"], the snapshot will contain the following attributes:
"Release": {
"ObjectID": 12345,
"Name": "2014 Q3",
"StartDate": "2014-07-01 18:00:00.0",
"ReleaseDate": "2014-10-01 16:59:59.0"
}Hydrating Project
The Name attribute of Project is available through hydration. When specifying "hydrate": ["Project"], the snapshot will contain the following attributes:
"Project": {
"ObjectID": 12345,
"Name": "Team Awesome"
}Pagination
The Rally Lookback API is constantly being updated with changes from Rally. When issuing requests for subsequent pages of results, it is important to include an ETLDate in your search criteria to ensure the results are consistent with previous requests. ETLDate is obtained from the response to your initial request.
{
"find": {
...,
"_ValidFrom" = "<ETLDate>"
},
"start": 20,
"pagesize": 20
}start indicates which record should
be the first record included in the results. It is similar to MongoDB's
"skip()".
pagesize indicates how many records
should be included in the results. If you specify a pagesize that exceeds the
maximum allowed pagesize, the lower value will be used.
<ETLDate> is the ETLDate
obtained from the initial request's response metadata.
Example:
Initial Request and Response:
{
"find": {
...
},
"start": 0,
"pagesize": 20
}
{
...,
"StartIndex": 0,
"PageSize": 20,
"ETLDate": "2014-03-03T15:43:34.887Z",
"Results": [
...
]
}Request for next page of results:
{
"find": {
...,
_ValidFrom = "2014-03-03T15:43:34.887Z"
},
"start": 20,
"pagesize": 20
}Note:
- The Rally Lookback API's
startoption is zero indexed. This differs from Rally's Web Services API parameter of the same name. - The default and maximum
pagesizemay change due to a number of factors, including if thefieldsparameter is set to "true". You can inspect the services status endpoint to see the current values for the default and maximum pagesizes.
Sorting
You specify sort using an object whose key is the field you want it sorted by and whose value is either 1 for ascending or -1 for descending.
{
"find": { ... },
"sort": { "_ValidFrom": -1 }
}Important: Sorting is only performed on indexed fields. If a sort is provided on unindexed fields, the query may still execute, but the sort will not be applied. The result will include a warning similar to the following:
Warnings: ["Sorting on unindexed fields is not supported. The following fields are not indexed - " ]Compressing Snapshots
For any given work item, there may be a large number of snapshots that capture
changes you don't care about. For instance, if you only want the field State, your results may contain
many snapshots where the change did not effect the State field.
Query:
{
"find": {
"ObjectID": 10448843790
},
"fields": ["State", "_ValidFrom", "_ValidTo", "ObjectID"],
"hydrate": ["State"]
}Results:
"Results": [
{
"_ValidFrom": "2013-02-07T02:15:58.719Z",
"_ValidTo": "2013-02-07T02:16:55.238Z",
"ObjectID": 10448843790,
"State": "Submitted"
},
{
"_ValidFrom": "2013-02-07T02:16:55.238Z",
"_ValidTo": "2013-02-07T03:17:59.444Z",
"ObjectID": 10448843790,
"State": "Submitted"
},
{
"_ValidFrom": "2013-02-07T03:17:59.444Z",
"_ValidTo": "2013-02-07T16:33:45.637Z",
"ObjectID": 10448843790,
"State": "Open"
},
{
"_ValidFrom": "2013-02-07T16:33:45.637Z",
"_ValidTo": "2013-02-11T18:02:45.815Z",
"ObjectID": 10448843790,
"State": "Open"
}
]The compress option allows you compact
the Results into fewer snapshots that represent changes to the fields you
requested in your query. The _ValidFrom and _ValidTo fields will be updated to
represent the time period for which those field values were in effect.
Query:
{
"find": {
"ObjectID": 10448843790
},
"fields": ["State", "_ValidFrom", "_ValidTo", "ObjectID"],
"hydrate": ["State"],
"compress": true
}Results:
"TotalResultCount": 10,
"CompressedResultCount": 2,
"Results": [
{
"_ValidFrom": "2013-02-07T02:15:58.719Z",
"_ValidTo": "2013-02-07T03:17:59.444Z",
"ObjectID": 10448843790,
"State": "Submitted"
},
{
"_ValidFrom": "2013-02-07T03:17:59.444Z",
"_ValidTo": "9999-01-01T00:00:00.000Z",
"ObjectID": 10448843790,
"State": "Open"
}
]Note:
- When using compression,
_ValidFrom,_ValidTo, andObjectIDmust be included in the fields. - The response now includes
CompressedResultCount. This is the total number of compressed snapshots returned. To determine the amount of compression, compare this value with theTotalResultCount.
Excluding count
The default behavior of the Rally Lookback API is to compute the number of items in the result of a query and return this as TotalResultCount. For large queries that involve traversing multiple pages, it may be more efficient for your application to simply issue subsquent requests for latter pages based on the value of "HasMore" and exclude the computation of the total result count.
{
"find": {"FormattedID":"S53625"},
"fields": ["ScheduleState", "_ValidFrom", "_ValidTo", "ObjectID"],
"includeTotalResultCount": false
}HasMore will always be present, regardless of the state of includeTotalResultCount.
Remove Unauthorized Snapshots
The default behavior of the Rally Lookback API is to return an error when a search would otherwise return results the user is not authorized to see. See the security model for more information about when and how this can occur.
It is possible to override this error behavior and have the API filter out unauthorized results, returning the remaining items.
{
"find": {"FormattedID":"S53625"},
"fields": ["ScheduleState", "_ValidFrom", "_ValidTo", "ObjectID"],
"removeUnauthorizedSnapshots": true
}This parameter is intended to streamline query development and debugging, not for use in production reports and charts. Enabling this option may cause different users to see different values for the same query. This is usually not the desired effect, since it can lead to confusion and misinterpretation of data.
Response
Default Fields
The following fields are returned when no fields parameter is specified:
{
"_rallyAPIMajor": "2",
"_rallyAPIMinor": "0",
"Errors": [],
"Warnings": [],
"TotalResultCount": 10,
"HasMore": true,
"StartIndex": 0,
"PageSize": 1,
"ETLDate": "2014-03-03T15:25:50.906Z",
"Results": [
{
"_id": "51410eaf6670f63793bd1d11",
"_ValidFrom": "2013-02-07T02:15:58.719Z",
"_ValidTo": "2013-02-07T02:16:55.238Z",
"ObjectID": 10448843790,
"Project": 279050021
}
]
}Result Metadata
The result object contains metadata describing the results that are returned.
_rallyAPIMajor,_rallyAPIMinor,Errors,Warning,TotalResultCount,StartIndex, andPageSizebehave identically as they do in Rally's Web Services API.CompressedResultCountcontains the result count when the compression is turned on.ETLDatecontains the timestamp of when the Rally Lookback API was last synchronized with Rally.- Some timing metrics and query debugging information may also be included in the results. These fields are subject to change and should not be used by production applications.
ETLDate
The Rally Lookback API is constantly being updated with recent changes from Rally. For brief moments during this update process, some data may not be self-consistent.
ETLDate is a field returned in the Results Metadata that points to the last time when all the changes have trickled across all effected documents and the data is self-consistent.
When using pagination or other types of follow-up queries, the ETLDate from the original response can be used to ensure subsequent queries do not include recent updates that have happened after the since the original query was executed.
{
"find": {
...,
"_ValidFrom": { "$lte": <ETLDate from original query> }
}
}Note: For active Workspaces, comparing the ETLDate timestamp to now will tell you roughly how far behind the Rally Lookback API is from the current time.
Additional Available Fields
The following fields are also available if specified with the fields parameter:
_UnformattedID(IfFormattedID="DE2345", then_UnformattedID=2345)- Revision information
_Revision. OID of revision record_RevisionNumber_User. User who made the edit_SnapshotNumberNameCustom string fieldsDragAndDropRank- All foreign key
ObjectIDs (Workspace, Iteration, Release, Parent, Requirement, etc.) - All numeric fields (
PlanEstimate,TaskActualTotal,TaskEstimateTotal, etc.) - All booleans
- All date fields
- Child Collections as lists of foreign key
ObjectIDs: Tags, Tasks, Defects, Children, Duplicates, Predecessors, Successors - Attributes for Iteration and Release (see Hydrating Iteration and Release for more details)
- Project name (see Hydrating Project for more details)
Unavailable Fields
The following fields are not available through the Rally Lookback API.
- Big/rich text fields (Description, Notes, etc.)
- Attachments
- Weblink fields
- LastBuild, LastRun, LastVerdict on TestCases
- Iteration or Release on Tasks
- Attributes for all unsupported entities (Workspace, Requirement)
- HasParent on HierarchicalRequirement
JSONP Support
The Rally Lookback API supports JSONP through
the use of the jsonp=<function_wrapper>
parameter. JSONP is only supported via GET.
GET:
https://rally1.rallydev.com/analytics/v2.0/service/rally/workspace/1234/artifact/snapshot/query.js?find={ObjectID:10448843790}&fields=["_ValidFrom","_ValidTo","ObjectID","State"]&start=0&pagesize=1&jsonp=myfunction
RESULT:
myfunction(
{
"_rallyAPIMajor": "2",
"_rallyAPIMinor": "0",
"Errors": [],
"Warnings": [],
"TotalResultCount": 10,
"HasMore": true,
"StartIndex": 0,
"PageSize": 1,
"ETLDate": "2014-02-28T16:19:06.684Z",
"Results": [
{
"_ValidFrom": "2013-02-07T02:15:58.719Z",
"_ValidTo": "2013-02-07T02:16:55.238Z",
"ObjectID": 10448843790,
"State":41529050
}
]
}
);Temporal Data Model
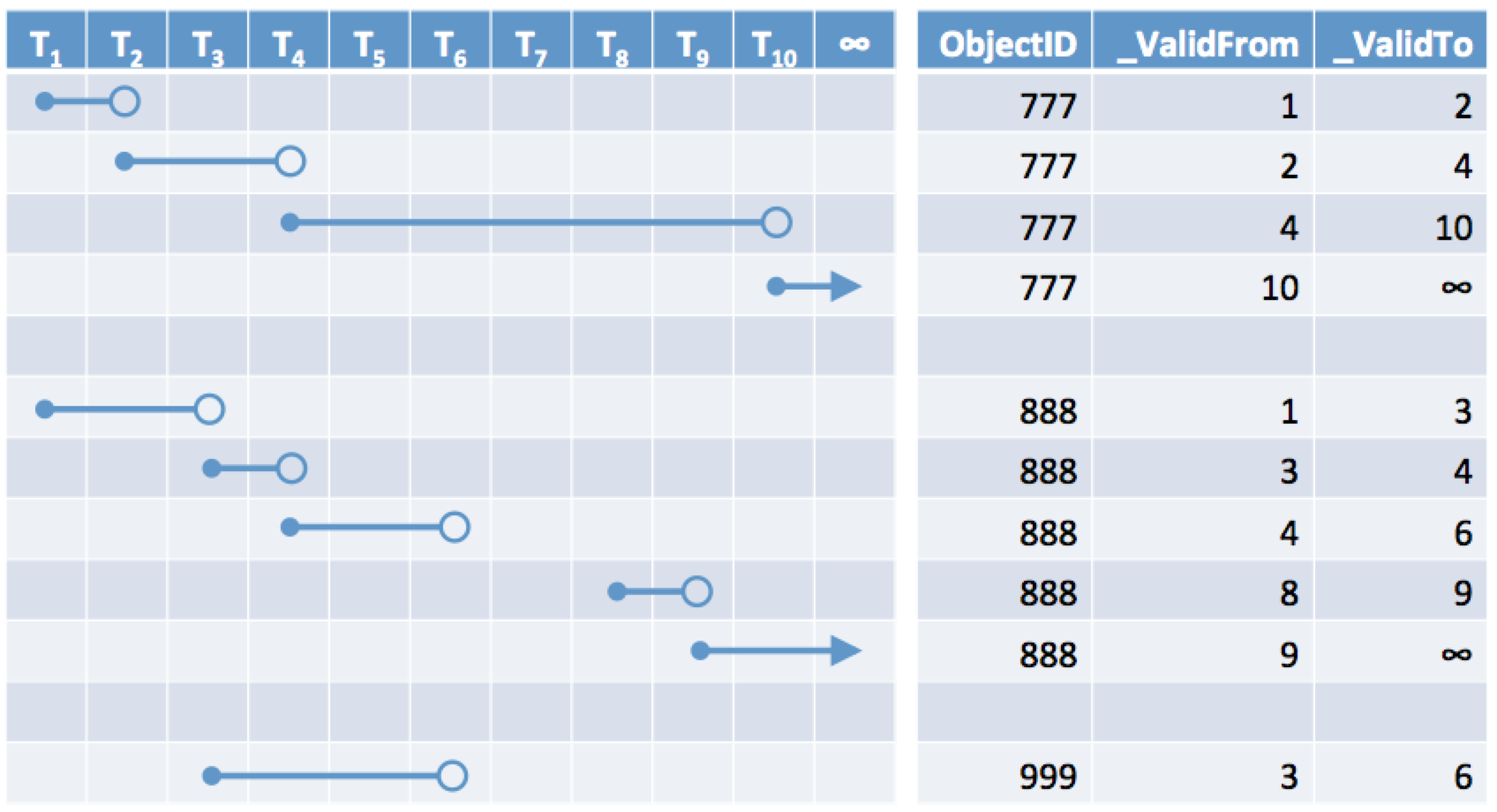
The above figure is provided to illustrate the temporal data model. Each row in
the above table represents a separate snapshot. The solid dot at the beginning
of each line segment and the open dot at the end of some of them indicates that
snapshot are inclusive of the start (_ValidFrom) and exclusive of the
end (_ValidTo). An arrow indicates that
the snapshot is still active (_ValidTo = ∞). There are a few
things we can observe:
- For each
ObjectID(777, 888, or 999), there is only one snapshot active at any given moment in time. ObjectID888 has a gap. This is how the data will look if the item is deleted (archived) and then restored from the recycle bin at a later time.ObjectID999 was deleted and never restored.
Now, let's look at how the temporal data model works when you submit an __At query.
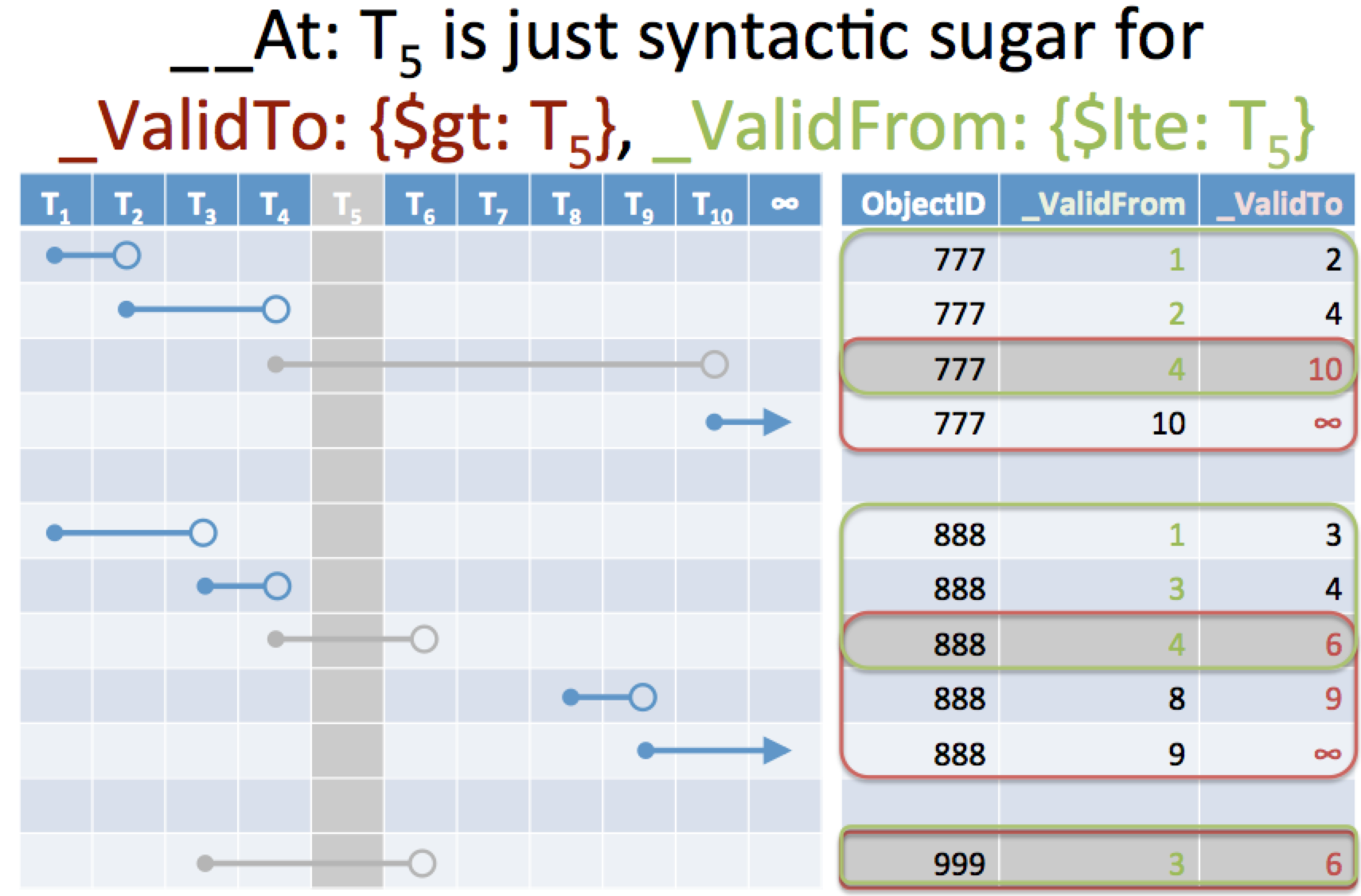
Each clause in a query will match a particular set. When you have more than one
clause "and"ed together, the combined phrase will match the intersection of the
sets from each of the clauses. So, by translating __At: T5 into _ValidTo > T5 and _ValidFrom <= T5 we only return
the snapshots that were active at T5.
More complicated temporal queries to find transactions that occur within a specific time frame or the amount of time that work spends in a particular logical state are possible using this temporal data model. Some of the more common uses are illustrated in the Scenarios section.
Working With Hierarchies
There are several different hierarchies that are represented in the documents.
Project hierarchy
The Project hierarchy is also represented as an array starting at a root Project for this Workspace. So if work item 777 is at the bottom of this Project hierarchy:
- Project 7890
- Project 6543
- Project 3456
- Work item 777
- Project 3456
- Project 6543
The document for work item 777 would look like this:
{
"ObjectID": 777,
"Project": 3456,
"_ProjectHierarchy": [7890, 6543, 3456],
...
}To retrieve all work items that are in Project 7890 or any of its child projects, you would simply include this clause in your query:
"_ProjectHierarchy": 7890Project Scope Up
If you want to accomplish the equivalent of projectScopeUp, you'll need to submit two queries: There are two conditions:
projectScopeUpin combination withprojectScopeDownprojectScopeUpWITHOUTprojectScopeDown.
For projectScopeUp in combination with
projectScopeDown, you would:
\1. Submit the query like above and keep the results as part of your result set. Let's say we're going to scopeUp on 3456, you would say:
"_ProjectHierarchy": 3456\2. When you get that response, inspect the _ProjectHierarchy field of any of the responses that come back. For all of the values before the one you are interested in (3456 in this example), build another array to pass back into a $in clause ("[7890, 6543]" in this example). Then submit a query like this and add it to the earlier results:
"Project": {"$in": [7890, 6543]}For projectScopeUp WITHOUT projectScopeDown, you would:
- Submit the same query as step 1 above but set the pagesize to 1 (This is favored over simply querying "Project: 3456" because it has a lower chance of hitting the problem in the note below).
- Inspect the results and submit the following:
"Project": {"$in": [7890, 6543, 3456]}
Result: what comes back is projectScopeUp without projectScopeDown.
Note: there is a risk that there are no results from the initial
query of _ProjectHierarchy: 3456.
In that case, this approach will not work.
Work Item Hierarchy
The work item hierarchy works the same way using the _ItemHierarchy field. So if you have this hierarchy:
- Story 333
- Story 444
- Story 555
- Story 666
- Defect 777
- Task 12
- Task 13
- Defect 777
- Story 666
- Story 888
- Story 999
- Story 555
- Story 444
The document for Story 666 would look like this:
{
"ObjectID": 666,
"Parent": 555,
"_ItemHierarchy": [333, 444, 555, 666],
...
}To retrieve all Stories that descend from Story 333 (includes 333, 444, 555, 666, 888, and 999 but not Defect 777), you would include this clause in your query:
{
"_ItemHierarchy": 333,
"_TypeHierarchy": "HierarchicalRequirement"
}ItemHierarchy can also be queried by UUID:
{
"_ItemHierarchyUUID" : "cb2cf39d-74f3-4b22-bee5-d2dea4a4bc10"
}Note that _ItemHierachy will cross work item type boundaries. The document for Task 12 would look like this:
{
"ObjectID": 12,
"Parent": 777,
"_ItemHierarchy": [333, 444, 555, 666, 777, 12],
...
}So, if you wanted all of the Tasks that were descendant from some high level story like Story 333, you could get that with this query clause:
{ "_ItemHierarchy": 333, "_TypeHierarchy": "Task" }
Leaf Stories and Portfolio Items
You can get back leaf Stories and Portfolio Items with one of these query clauses:
For just Stories:
"Children": nullFor Stories or Portfolio Items:
"$or": [
{"_TypeHierarchy": "HierarchicalRequirement", "Children": null},
{"_TypeHierarchy": "PortfolioItem", "Children": null, "UserStories": null}
]Work Item Type Hierarchy
While this may not be as obvious at first, there is also a _TypeHierarchy hierarchy in Rally. A Defect is also an Artifact, is also a WorkspaceDomainObject, etc. We represent this in the Rally Lookback API like this:
{
"_TypeHierarchy" : [ "PersistableObject", "DomainObject", "WorkspaceDomainObject", "Artifact", "Defect" ],
...
}The contents of the _TypeHierarchy are the Type Definitions including both generic and workspace-specific objects. Generic Type Definitions include:
- PersistableObject
- DomainObject
- WorkspaceDomainObject
- Artifact
- Defect
- Task
- TestCase
- DefectSuite
- HierarchicalRequirement
- PortfolioItem
The way queries against the Rally Lookback API engine work, if you include:
"_TypeHierarchy": "Defect"as a clause in your query, it will match the _TypeHierarchy field in the example above and would query for all Defects. This queries for all Defects, but is also more powerful since you can query for all Artifacts with:
"_TypeHierarchy": "Artifact"or all Portfolio Items with:
"_TypeHierarchy": "PortfolioItem"There is no need to say "contains" or provide any additional operator for this to match. It knows that if the target value is an array, any element of that array is sufficient for a match. For the purposes of querying by type, you can specify either the generic oid or workspace-specific oid, if you know it.
Example Scenarios
The examples below show you how to retrieve data in a variety of scenarios.
1. Retrieve the entire history of a particular Rally work item
{ "ObjectID": 777 }You could just as easily have queried on FormattedID.
2. Retrieve the "current" version of a particular Rally work item
{ "ObjectID": 777, "__At": "current" } // "__At" has two underscoresThe "current" will be replaced with the ETLDate timestamp which may be anywhere from a few milliseconds to a few minutes behind transactions in the primary Rally UI.
Note that the __At field is not actually a field
in the Rally Lookback API. It’s syntactic sugar equivalent to:
{
"ObjectID": 777,
"_ValidFrom": {"$lte": "current"},
"_ValidTo": {"$gt": "current"}
}You should feel free to explicitly use _ValidTo and _ValidFrom depending upon your
needs.
3. Retrieve a particular Rally work item as it looked on a particular date
{"FormattedID": "DE2345", __At:"2011-01-10T00:00:00Z"}The date in the example above is midnight on January 9, 2011 in the Zulu timezone. It is preferable to specify the following day "2011-01-10T00:00:00Z" than to use 24:00:00 on the day in question, but "2011-01-09T24:00:00:00Z" is equivalent.
Further, it is permissible to exclude the lower order elements when they are zero. So, you could have written "2011-01-10T00Z".
Also, note that we used the "FormattedID" field instead of the ObjectID for this example. In the
example below, we omit the "DE" prefix. The FormattedID is actually stored
without the "DE" in the _UnformattedID field and it is stripped from queries so
the below example is equivalent.
{
"_UnformattedID": "2345",
"_TypeHierarchy": "Defect",
"__At": "2011-01-10T00:00:00Z"
}Note: the above translation example works well when a single FormattedID is specified. However, it's less obvious how it would work if multiple kinds of artifacts were specified. For instance, how would it behave if it received this:
"FormattedID": {"$in" : ["DE2345", "S1234"]}The above example $in clause is supported by in the
Rally Lookback API because it automatically converts it to an
appropriate $or clause. $exists, equals ":" are supported in this circumstance
but other operators may not be supported. If you have need to compose a
complicated query, it is best to use ObjectID rather than FormattedID. There is limited
support for: $and, $or, $ne, $in, and $exists with FormattedID, although not all
recursive combinations of $and and $or will work.
Operators not supported include $lt, $lte, $gt, $gte, $all, $nin, $nor.
4. Retrieve a set of defects as they looked on a particular date
{
"_ProjectHierarchy": 7890,
"_TypeHierarchy": "Defect",
"Priority": "High Attention",
"__At": "2011-02-01T00Z"
}The above query will return the list of defects in Project 7890 and its
sub-projects that had the their Priority field set to "High Attention" as of the
end of January, 2011. Notice how the __At field is set to February 1.
Our own charts will follow the convention of using 00:00:00.000 of the first day
of the following month when trying to identify the state as of the end of a
particular month. We will search for entities whose _ValidFrom and _ValidTo dates are "<" and
">=", respectively to the provided timestamp.
5. Retrieve defects that experienced a particular state transition in July 2011
{
"_TypeHierarchy": "Defect",
"Project": 7890,
"_PreviousValues.c_KanbanState": {"$lt": "Completed"},
"c_KanbanState": {"$gte": "Completed"},
"_ValidFrom": {
"$gte": "2011-07-01TZ",
"$lt": "2011-08-01TZ"
}
}Because the Rally Lookback API doesn’t know anything about ordering of the AllowedValues for the State field, it will look up your AllowedValues for the State field and convert the above query to something like:
{
"_TypeHierarchy": "Defect",
"Project": 7890,
"_PreviousValues.c_KanbanState": {"$in": [null, "Idea", "Defined"]},
"c_KanbanState": {"$in": ["Completed", "Accepted", "Released"]},
"_ValidFrom": {
"$gte": "2011-07-01TZ",
"$lt": "2011-08-01TZ"
}
}The State field is "required" (not-nullable) in Rally but the null value is considered the lowest value in the ordered list of AllowedValues so it is included in every such query regardless of the current "required" setting for this field. The thinking is that you may have recently set the field to "required" meaning that there might be some old snapshots where the value is missing. This approach handles all cases as expected.
6. Find out how long a work item has been in its current KanbanState
{
"find": {
"ObjectID": 777,
"c_KanbanState": <current KanbanState>,
"_PreviousValues.c_KanbanState": {"$ne": <current KanbanState>}
},
"sort: {"_ValidFrom": -1},
"pagesize": 1
}This will return the snapshot of the most recent time that ObjectID 777 had transitioned into
its current KanbanState. This assumes you have previously retrieved the latest
version of ObjectID 777 and know its current
KanbanState. The _ValidFrom field in the record that
is returned is the timestamp of when it entered the current KanbanState. You
simply subtract that from today() to find out how many days it has been in this
KanbanState.
If you batched up a list of work items, you could replace the ObjectID clause with:
"ObjectID": {"$in": [<your list of ObjectIDs>]}and get them all back at once. However, you'd have to drop the sort and limit clauses and figure out on the client which one was the last one for each work item. You can decide which is better for your situation.
- Create a Portfolio Item, or Story (epic) burn chart... or cumulative flow chart
If you have this:
- Portfolio Item 333
- Story 444
- Story 555
- Story 666
- Defect 777
- Task 12
- Task 13
- Defect 777
- Story 666
- Story 888
- Story 999
- Story 555
- Story 444
To get all leaf stories that descend from PI 333 (666, 888, and 999) on a particular date and get the PlanEstimate, and ScheduleState fields on January 1:
{
"find": {
"_ItemHierarchy": 333,
$or [
{"_TypeHierarchy": "HierarchicalRequirement", "Children": null},
{"_TypeHierarchy": "PortfolioItem", "Children": null, "UserStories": null}
],
"__At": "2011-01-01T00:00:00.000Z"
},
"fields": ["PlanEstimate", "ScheduleState"]
}You would then vary the __At clause value to get the other
points for the chart.
- Provide analytics about Defects below some high-level Story
"From the EMC... A strong interest was expressed in rolling up defect information by feature such as for defects linked to a set of stories which roll up to epics and to features and provide some analysis at the epic level about those defects."
So, if you have this:
- Story 555
- Story 666
- Defect 777 (via the Requirement field)
- Task 12
- Defect 000
- Task 13
- Defect 777 (via the Requirement field)
- Story 888
- Defect 999
- Story 666
and you have a query clause like this:
"_ItemHierarchy": 555it will match Story 555, Story 666, Defect 777, Task 12, Defect 000, Task 13, Story 888, and Defect 999. Adding a restriction on "_TypeHierarchy": "Defect" will get you just the Defects. So, for EMC's scenario, you want just Defect 777, Defect 000, and Defect 999:
{
"_ItemHierarchy": 555,
"_TypeHierarchy": "Defect"
}- Create your own throughput report except use the state transition to Completed instead of Accepted
You can see from scenario 5 how to sense when a particular state transition occurs. You can expand on this to build your own throughput report and control what boundary is counted. The example below keys off of the "State" field but it could just as easily have keyed off of a custom field like "KanbanState".
{
"find": {
"_ProjectHierarchy": 7890,
"State": {"$gte": "Completed"},
"_PreviousValues.State": {"$lt": "Completed"},
"_ValidFrom": {
"$gte": <first day of some month>,
"$lt": <first day of next month>
}
},
"pagesize": 0
}By setting the pagesize to zero, the response would not contain any of the actual work items. However, the header information for the response would contain the count needed for this Throughput metric in the TotalResultCount field. For now, if you want more than the count, you'll need to do that math on the client.
You would then make multiple requests covering additional months until you had the data you needed.
Note: The above query will not take into consideration work items where the state regressed (e.g. "Completed" -> "In-Progress"). In a true Throughput report, you should subtract the work items that regress.
Dates, Timestamps, and Timezones
All date and times in the Rally Lookback API are GMT and are communicated to/from using ISO-8601 format using the following possible notations:
- "2011-02-01T00:00:00.000Z" - "Z" means "zulu" time or GMT.
- "2011-02-01T00:00:00Z" - You can omit the milliseconds with "Z" form. In fact, you can omit all of the lower order values that you want to be zero. "2011-02-01T00Z" is equivalent.
Note: If you want midnight in your timezone, you have to shift the time to GMT when submitting a query. To specify a range of all change events that occurred on January 1, 2011 in eastern time zone, you'd start with 2011-01-01T05Z and end with 2011-01-02T05Z.
Caveats
- Supported entities The Rally Lookback API is focused on PortfolioItems, Hierarchical requirements (User Stories), Defects, TestCases, and Tasks for now. The API may give you access to other entities, but for these other entities, you should have lower expectations of stability, documentation, and indexes and denormalization for efficient querying. Portfolio Items are included and participate correctly in the _ItemHierarchy.
- Unsupported entities There are entities which the Lookback API does not support at this time. No information on Test Sets is returned by the Lookback Api.
- Highly selective criteria. In order to limit the load that any one query will place on the service and to ensure that every query uses a fairly selective index, we may place restrictions on queries. For instance, we will allow you to get all versions of a single work item, but we may not allow you to get all versions of every work item in a project. On the other hand, we will allow you to get a single moment-in-time view of all work items in a single project but may restrict deep project hierarchies. Project hierarchy queries may be limited by how many projects they encompass and/or may require that you specify some other criteria like State, Priority, etc. The definition of "highly selective" will be a moving target during the open preview period. Our current plan is to start out with no such restrictions and add the restrictions as use cases are better defined. Also, these restrictions may become more liberal when throttling is implemented.
Paradigm Shifts
The past is unchangeable
We want to encourage you to think of the past as unchangeable. This is not as obvious as it sounds and it's actually a departure from the way some of our current reports work. This is best explained with an example. Let's say you want to trend the count of all open P1 defects within in a particular project over time. One way to do this would be to first find all P1 defects that are currently in that project and then look at the history of each of those defects to find when they were open and resolved. Using this approach, any defects that had moved into the project during the time of interest would be included in ALL of the data points on the trend line and any that had moved out of the project at an earlier date would be counted in NONE of the points. Similarly, if they didn't start out as P1s or were downgraded from P1 priority later, that wouldn't matter. By first finding the defects that are NOW in the project and NOW have P1 priority, you have essentially changed the past.
Rather, we want you to think of the generation of this defect trend line as the application of the same query at particular moments in the past. So, if you want to trend by month starting three months ago, you run the query against the data as it looked three months ago, and then you run it again against the data as it looked two months ago, and then finally against the way it looked at the most recent month boundary. If a defect was assigned to your project three months ago but isn't now, it will be included in the count back then but excluded from this month's count.
The reason for this design choice is simple - by taking this approach, we can warehouse the aggregations from any queries that you run for fast retrieval the next time they are run. It also turns out that this is usually the preferred behavior. We decided to trade-off the ability to perform the alternative type queries for those rare cases where it is preferable in exchange for a huge speed and simplicity advantage for the common case.
A Different Security Model
The current Rally security model is based upon pre-identifying the projects for which you currently have permission BEFORE it even knows what data satisfies your request. Once you are authenticated and your current project scope is set, we then know all of the projects within the project scope for which you currently have permission. This list of permissible projects is pre-populated upon each request and it becomes a part of any queries that are submitted to the database ("... WHERE project IN [039284, 039284, 093923]..." for example). This works great for processing the typical read and edit transactions that you do in Rally every day, but it's not ideal for analytics. Under the current model, it's possible for two users to request the exact same report but get back different results because they have different permissions. Worse, the current analytics engine has no way to warn users of this because, under the current security model, it has no way to know it's missing some data. The "WHERE projects IN ..." clause is automatically added to every query made by the current analytics engine.
We wanted to fix this, so the Rally Lookback API's security model doesn't check your permissions until AFTER it has figured out what data matches your query. Every restricted entity (includes User Stories, Defects, and Tasks) in the API has a project field. After a query against these entities is complete, it will extract the set of projects mentioned in the returned entities and compare it to the list of projects for which you have permission. If you have permission for all of them, no worries. If you are missing read permission for one or more, the request will return with an error listing the projects for which you do not have permission.
Note: this new security model interacts with the "past is unchangeable" concept. The list of projects will include projects that were pointed to by past versions of work items even if those past projects have been deprecated and contain no work at this time.
We understand that this new security model will require an adjustment for some and be too restrictive for others. We have also envisioned the need to allow you to return data (maybe with certain fields missing; maybe only aggregated data) even if it comes from projects for which you do not even have read permission. If the need for this arises, we will make it a setting(s) so that folks who desire the more restrictive model will have that choice.
FAQs
Q: Is this how things are actually stored?
A: Pretty much. We're trying to avoid impedance mismatch between tables and objects. We're trying to make it fast, clean, and simple.
Q: Why is the Rally Lookback API so close to the native MongoDB interface?
A: We like it. In fact, we had an earlier design that was based upon another analytics oriented database technology (CouchDB) and for that design we were still borrowing the MongoDB syntax.
There are all sorts of derivatives of SQL (JQL, MDX, TSQL, etc.). The next phase of evolution for web applications will see an explosion of JSON-based query languages. With MongoDB's popularity, we wouldn't be surprised if others built upon it.
Note that the API is not blindly passing along whatever you give it. We convert your find clauses into objects; validate and modify them; and then build a query for MongoDB. If we ever have to go away from MongoDB, we will re-implement the query language and translate it to whatever technology is chosen.
Q: Why does this Rally Lookback API use "fields" rather than "fetch" like Rally's standard web services API?
A: We might be convinced otherwise if there is an uproar over this difference. However, we felt that the semantics for "fetch" are overloaded. It both hydrated the sub-objects as well as specified what fields to return. We wanted to make those two things separate. Also, we wanted to support the use of the slice operator for specifying partial Array values to be returned. See Fields section for details on how the slice operator works.
Tips and Tricks
1. No quotes around ObjectIDs or Boolean values We store a lot of ObjectIDs in the Rally Lookback API. It's tempting to write a query like this:
"find": {"ObjectID": "123456789", "Blocked": "true"}But that won't work. Rather, you should leave the quotes off of the number as well as the Boolean value so it should read:
"find": {"ObjectID": 123456789, "Blocked": true}2. Think JavaScript literals NOT pure JSON The Rally Lookback API accepts a loose form of JSON that more closely follows the rules of JavaScript literals than JSON.
In JSON, this is invalid:
{"a": 'test'}For two reasons: (1) There are no quotes around the key, and (2) I used single quotes instead of double quotes around the value.
However, the above works just fine in the Rally Lookback API as it would work just fine if you embedded it in your JavaScript as a literal.
Keep in mind that sometimes you have to put quotes around your keys when they contain certain characters... just like in JavaScript literals. So you can't say:
{"_PreviousValues.a": 'test'}But you can say:
{"_PreviousValues.a": 'test'}Note: the Rally Lookback API will always return valid JSON. Also, it is always safe to use valid JSON in your request submissions.
3. Do you support XML or CSV? At this time, the Rally Lookback API is JSON-only. We may support XML and CSV at a later date.
4. Why REST-ish? The Rally Lookback API is REST(-ish) only. There is no SOAP interface. We say REST-ish, because you can use POSTs against this API as an alternative to GETs and the reference-following mechanism recommended (HATEOAS) in Roy Fielding foundational dissertation on REST are not completely followed by this API. We have considered adding a "next", which is the only appropriate application of HATEOAS that we can envision for a read-only API such as this.
5. How do I write my App so it will not break when the Rally Lookback API is updated? Except to fix a defect, when we need to make any upgrade to the API that would break backward compatibility, we will increment the version number (from v2.0 to v2.1 for example). However, we will not remove access to the old version. Any App you write should specify "v2.0" in the URL when it calls this API. When we upgrade, v2.0 will continue to operate as it did before. You would need to change your calls to v2.1 to take advantage of the new functionality in the new version.
Note, however, that we may make backward-compatible changes to the Rally Lookback API without incrementing the version number. For example, the addition of query functionality to this API would not require a version increment. However, removing or changing the syntax for some functionality would require a revision. Because there is no WSDL to change in a REST API as there would be in a SOAP API, this less strict approach should be acceptable for maintaining backward compatibility.
Client-provided Integration Information
Rally collects the following non-proprietary and non-confidential information as optionally provided by the user. This information is used to understand usage patterns and improve Rally's products.
The information requested is:
- Name: Integration name, such as "Subversion Plugin".
- Vendor: Integration vendor, such as "Broadcom".
- Version: Integration version, such as "2.01".
- OS: Client operating system information, such as "Linux 2.6.18-8.1.1.el5 amd64".
- Platform: Various platform information, such as the JDK version or Ruby runtime version, such as "Java 1.6.0_41".
- Library: Library framework information, such as "Rally Ruby REST API" or "Apache Axis 1.4".
These values can be provided to Rally through the use of the following custom HTTP Headers -
- X-RallyIntegrationName
- X-RallyIntegrationVendor
- X-RallyIntegrationVersion
- X-RallyIntegrationOS
- X-RallyIntegrationPlatform
- X-RallyIntegrationLibrary
API Deprecation Policy
Broadcom may, from time to time, modify, discontinue or deprecate any API's, Language Specific Toolkits, and SDK's, but will use commercially reasonable efforts to support the previous version of any API's, Toolkits or SDK's for one year - referred to as the deprecation period (except where doing so (i) would create a security threat or intellectual property issue, (ii) is financially or technically unfeasible, or (iii) is necessary to comply with applicable laws or governmental requests).
After the one year deprecation period expires for that product (API,Toolkit,SDK,etc.), it is no longer supported, maintained or assumed to be in a state that is usable by the customer. Broadcom has the right to terminate versions where the deprecation period has expired. This deprecation policy will begin starting November 1, 2012 with the first set of APIs and toolkits being no longer supported on November 1, 2013.
Requests against deprecated and not supported versions of the API will return a warning indicating that the state is either Deprecated or Not Supported.
Broadcom reserves the right to modify this API Deprecation Policy at any time, in its sole discretion.